Abstract
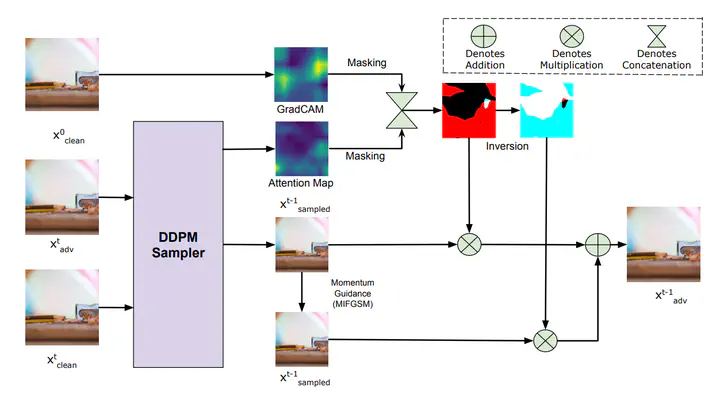
Adversarial perturbations generated using GANs or diffusion models often suffer from issues such as poor quality, long generation runtime, and high computational costs. Additionally, diffusion models are known to have been trained on large sets of training data, which makes it hard to control the generated data. Thus, we explore the plethora of feature variations in the diffusion model backbone to select the right properties for unintended perturbations. To this end, we propose TAIGen, a novel black-box, training-free adversarial attack method. TAIGen utilizes unconditional diffusion models to generate perturbations efficiently in just a few sampling steps. Our approach introduces a selective channel-based mechanism that integrates attention maps and GradCAM that are both robust and imperceptible. These perturbations are also transferable to unseen classifiers, increasing their overall impact. The effectiveness of TAIGen is validated across the ImageNet, CIFAR-10, and CelebA-HQ datasets. In the challenging black-box setting on ImageNet using VGGNet as the source model, TAIGen achieves attack success rates of 70.6% on ResNet, 80.8% on MNASNet, and 97.81% on ShuffleNet.